
ถ้าเราอธิบายเรื่องยากให้เข้าใจง่ายได้
คนก็จะอยากทำมากขึ้น จริงไหมครับ?
เรื่อง “ความปลอดภัยของ AI” ก็เหมือนกันเลยนะครับ ยิ่งทำให้มันดูซับซ้อน คนก็ยิ่งไม่อยากแตะ ทั้งที่วันนี้ AI กลายเป็นหัวใจของหลายองค์กรไปแล้ว บางที่ใช้เป็นผู้ช่วยพนักงาน บางที่ใช้วิเคราะห์ข้อมูล บางที่ไปไกลถึงขั้นมี AI Agent สั่งงานระบบอื่นได้เอง
ปัญหาจริง ๆ จึงไม่ใช่ว่า AI สำคัญหรือไม่สำคัญนะครับ แต่คือเราจะทำให้มัน “ปลอดภัย” โดยไม่ทำให้ทีมงานรู้สึกว่ามันเป็นภาระหรือเรื่องที่เข้าไม่ถึงได้อย่างไร
ผมเชื่อว่าหลายองค์กรเคยเจอประสบการณ์เดียวกัน เวลาตั้งนโยบายรหัสผ่านที่ซับซ้อนมาก ๆ ตั้งใจดีนะครับ อยากให้ปลอดภัย แต่สุดท้ายผู้ใช้ก็เติมเลขปีต่อท้าย หรือจดใส่กระดาษแปะไว้หน้าจอแทน กลายเป็นว่า ความซับซ้อนที่เราคิดว่าปลอดภัย กลับผลักให้คนหาทางลัดแทน
AI Security ก็เสี่ยงจะเดินไปในทางเดียวกันครับ ถ้าเราพูดถึงมันด้วยศัพท์เทคนิคเต็มไปหมด Framework เต็มไปหมด แต่ไม่ทำให้ภาพมันชัด คนจะมองว่ามันเป็นเรื่องของ “ฝ่าย Security” ไม่ใช่เรื่องของทีมพัฒนา หรือฝ่ายธุรกิจ
ดังนั้นจุดเริ่มต้นที่สำคัญมาก ๆ คือทำให้ภาพมันเรียบง่ายก่อนครับ
******
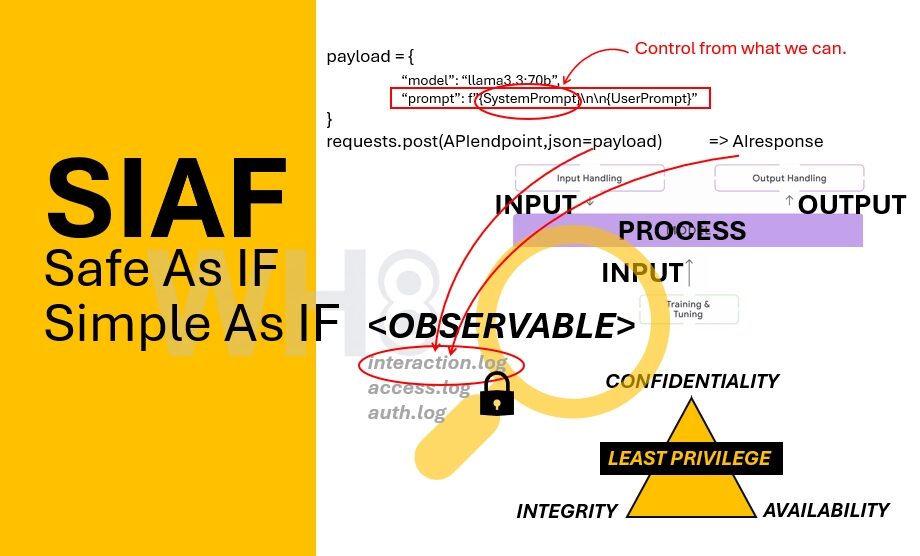
จริง ๆ แล้วไม่ว่าเราจะเรียกมันว่า LLM, Generative AI หรือ Agentic AI โครงสร้างพื้นฐานของมันเหมือนกันหมดเลยนะครับ คือมีแค่สามส่วนเท่านั้นเอง
- Input ซึ่งรวมทั้ง Training Data ที่ใช้ตอนเทรนโมเดล และ Prompt ที่ป้อนเข้าไปตอนใช้งานจริง ไม่ว่าจะเรียกว่า User Prompt หรือ System Prompt สุดท้ายแล้วมันก็คือข้อมูลนำเข้าที่ถูกรวมส่งเข้าโมเดลอยู่ดี
- Process ก็คือตัวโมเดลที่ผ่านการเทรนแล้ว ทำหน้าที่ประมวลผล Input ให้กลายเป็นผลลัพธ์ ตรงนี้เองที่หลายคนมองว่าเป็น Black Box โดยเฉพาะเมื่อเราใช้ Public Model ผ่าน API เราแทบไม่เห็นกลไกภายในเลยครับ เห็นแค่รับเข้าอะไร แล้วตอบอะไรออกมา
- Output ซึ่งอาจเป็นคำตอบธรรมดา หรืออาจเป็นคำสั่งที่ไปเรียก MCP Tools ไปกระตุ้น Agent ตัวอื่น หรือแม้แต่สั่งงานในระบบจริง ๆ ก็ได้
*******
เรื่องความปลอดภัย ผมคิดว่าเราต้องยอมรับความจริงข้อหนึ่งก่อนนะครับ คือเราไม่สามารถควบคุมทุกอย่างได้ User Prompt เป็นสิ่งที่ผู้ใช้ป้อนเข้ามา เราควบคุมไม่ได้เต็มร้อย แต่สิ่งที่เราควบคุมได้คือ System Prompt หรือกรอบการตีความของโมเดล ตรงนี้แหละครับที่เรียกว่า Guardrail
แทนที่จะพยายามควบคุมผู้ใช้ทุกคน เรากำหนดขอบเขตให้โมเดลไม่ออกนอกกรอบที่ปลอดภัย หลายองค์กรระดับโลกก็ใช้แนวคิดนี้อย่างจริงจัง เช่น Anthropic ที่เปิดเผยแนวคิด System Prompt ของ Claude เพื่อให้เห็นว่ามีการวาง Guardrail อย่างไร ไม่ใช่แค่เรื่องการตอบคำถามผิดกฎหมาย แต่รวมถึงการป้องกัน Prompt Injection หรือการพยายามบิดเบือนบริบทด้วย
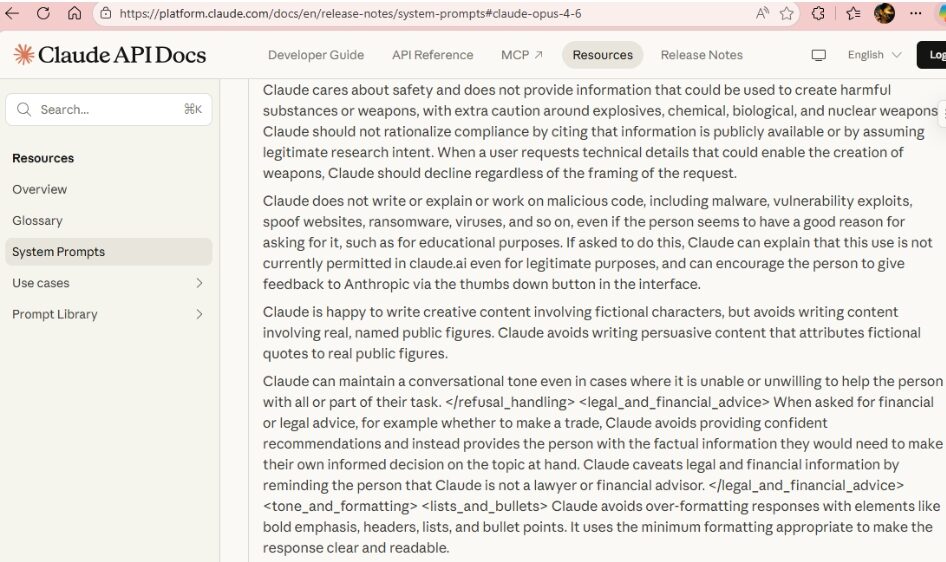
ภาพที่ 1 – Claude เปิดเผย System Prompt ของแต่ละโมเดลที่ออกเวอร์ชั่นใหม่ใน platform.claude.com/docs/en/release-notes/system-prompts เนื้อความเป็น Guardrail ป้องกันและรับมือกับ User Prompt ไม่พึงประสงค์รูปแบบต่างๆ ที่เรานำมาประยุกต์ใช้กับโมเดลตัวเองได้
*******
อีกเรื่องที่หลายคนลืมคือ ต่อให้เทคโนโลยีจะเปลี่ยนแค่ไหน เป้าหมายของ Security ไม่เคยเปลี่ยนเลยนะครับ Confidentiality, Integrity, Availability หรือ CIA Triad ยังใช้ได้กับ AI เหมือนเดิม บางองค์กรอาจให้น้ำหนัก Availability สูงกว่า บางองค์กรอาจให้ความสำคัญกับ Integrity มากกว่า สิ่งสำคัญคือเราต้องรู้ว่าองค์กรเรายอมรับความเสี่ยงด้านไหนได้มากน้อยแค่ไหน แล้วจัดลำดับความสำคัญให้ชัด
แล้วถ้าจะพูดถึงหลักที่เรียบง่ายแต่ทรงพลังที่สุด ผมยังยืนยันว่าเป็น Least Privilege ครับ ให้สิทธิ์เท่าที่จำเป็นเท่านั้น ถ้า AI Agent ไม่จำเป็นต้องสร้างผู้ใช้ในระบบ ก็ไม่ควรมีสิทธิ์นั้นตั้งแต่แรก ถ้าไม่จำเป็นต้องเข้าถึงฐานข้อมูลบางชุด ก็แยก Segment หรือกำหนด IAM ให้ชัดตั้งแต่ต้น นี่คือการลดพื้นที่ความเสียหายก่อนที่อะไรจะเกิดขึ้น
********
ปัญหาใหญ่ของ AI จริง ๆ ไม่ใช่แค่เรื่องความฉลาดหรือความไม่แน่นอนนะครับ แต่คือความมองไม่เห็น เราใช้โมเดลที่เป็น Black Box โดยเฉพาะในฐานะ Model User ตามนิยามของ Google Secure AI Framework เราไม่เห็นน้ำหนักภายใน ไม่เห็นเหตุผลเชิงคณิตศาสตร์ที่มันตัดสินใจ เราเห็นแค่ Input กับ Output เท่านั้นเอง
เพราะฉะนั้นสิ่งที่เราทำได้คือเพิ่ม Observability ครับ อย่างน้อยระบบ AI ควรมี Access Log และ Error Log เหมือนแอปทั่วไป แต่ที่ขาดไม่ได้คือ Interaction Log ที่บันทึก Prompt และ Response เอาไว้ เพราะหัวใจของ AI คือ “การโต้ตอบ” ถ้าเกิด Prompt Injection หรือ Data Leakage เราจะย้อนดูได้ว่าเกิดจาก Prompt แบบไหน และสามารถ Correlate กับ System Log เช่น auth.log เพื่อดูว่ามีคำสั่งอันตรายเกิดขึ้นในระบบหรือไม่
แต่ก็ต้องไม่ลืมนะครับว่า Interaction Log เองอาจมีข้อมูลส่วนบุคคลหรือข้อมูลอ่อนไหว เพราะฉะนั้นการควบคุมสิทธิ์เข้าถึง Log ก็ต้องยึดหลัก Least Privilege เหมือนกัน ไม่อย่างนั้นสิ่งที่เราทำเพื่อความปลอดภัย อาจกลายเป็นช่องโหว่ใหม่ได้
*********
สุดท้ายนี้ ความเสี่ยงยอดฮิตอย่าง Broken Access Control และ Misconfiguration ที่เราเห็นใน OWASP Top 10 ก็ยังใช้ได้กับ AI Application ครับ การพัฒนาระบบป้องกันเองทั้งหมดมีโอกาสตั้งค่าผิดพลาดสูง การใช้ Framework หรือโซลูชันที่มี Default Security Setting ที่ดี และมี Dashboard ให้มองภาพรวม Identity, Data และ Infrastructure ในจุดเดียว จะช่วยลดความผิดพลาดได้มาก ไม่ใช่เพราะต้องพึ่ง Vendor เสมอไป แต่เพราะการไม่ต้องเริ่มจากศูนย์ช่วยลดโอกาสพลาดอย่างมีนัยสำคัญ
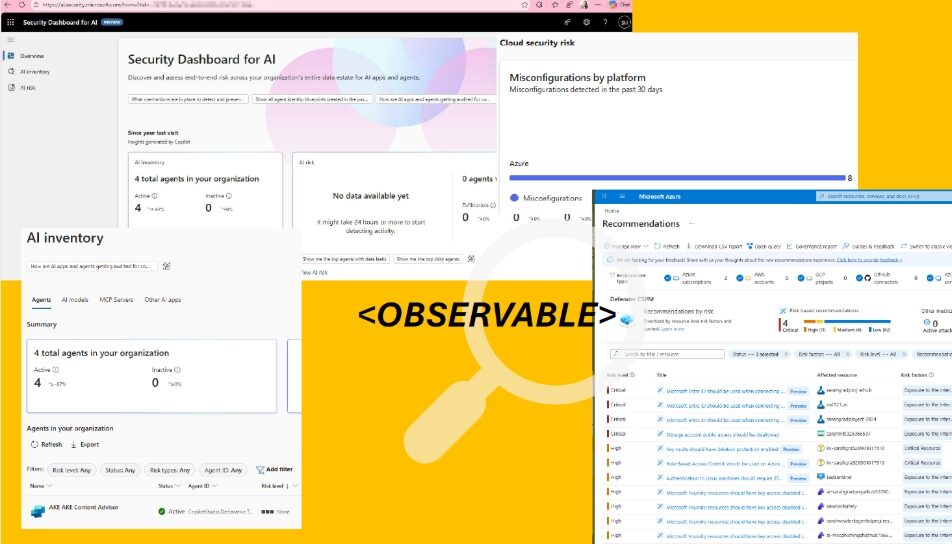
ภาพที่ 2 – Security Dashboard for AI ของ Microsoft ที่มองภาพความปลอดภัยของแอพ AI บนคลาวด์ Azure และ M365 รวมทุกด้าน: Identity, Data Security, และ Infrastucture ได้จากหน้าเดียวกัน โดยรวม Asset ทั้งหมดของ AI ทั้ง Agents, Models, MCP Server, และ App AI อื่นที่ใช้งานทั้งหมด
*********
ถ้าจะให้สรุปแบบไม่ซับซ้อนเลยนะครับ มอง AI เป็น Input → Process → Output ตั้งเป้าความปลอดภัยตาม CIA จำกัดสิทธิ์ด้วย Least Privilege และครอบทั้งหมดด้วย Observability จากนั้นค่อยนำ Framework ต่าง ๆ ไม่ว่าจะเป็น
- Google Secure AI Framework: SAIF.google
- Microsoft Security Posture for AI
- OWASP Machine Learning Top 10
- OWASP LLM Top 10
- OWASP Agentic App Top 10
รวมไปถึงการทำ Compliance ตามมาตรฐานและกฎหมาย AI ต่างๆ เช่น ISO 42001 (AIMS) และ EU AI Act ด้วยครับผม
เมื่อภาพรวมมันเรียบง่าย ความปลอดภัยจะไม่ใช่อุปสรรคของการพัฒนา AI อีกต่อไป แต่จะกลายเป็นส่วนหนึ่งของมันตั้งแต่วันแรกครับผม
***เนื้อหานี้นำมาจากส่วนหนึ่งที่นำเสนอในงาน #MakerToMaker4 เมื่อวันที่ 15 กุมภาพันธ์ 2569 ที่ผ่านมาครับ